El aprendizaje supervisado es uno de los enfoques más fundamentales y ampliamente utilizados en el campo del aprendizaje automático (machine learning). Este método se basa en el uso de datos etiquetados para entrenar algoritmos, permitiendo a las máquinas aprender y hacer predicciones con alta precisión. Desde la clasificación de correos electrónicos como spam hasta la predicción de precios de viviendas, el aprendizaje supervisado es esencial para una amplia gama de aplicaciones tecnológicas en nuestro día a día.
Aprendizaje Supervisado
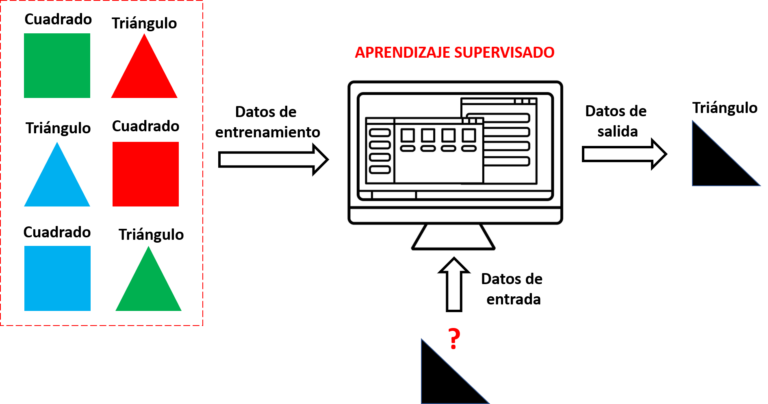
En términos simples, el aprendizaje supervisado implica entrenar un modelo utilizando un conjunto de datos en el que cada ejemplo está asociado con una etiqueta o resultado correcto. La premisa básica es que el modelo puede aprender de estos ejemplos y generalizar este conocimiento para predecir las etiquetas de nuevos datos no vistos.
Componentes Clave del Aprendizaje Supervisado
- Datos de Entrenamiento: Este es un conjunto de datos etiquetados, donde cada entrada viene con una salida correspondiente. Por ejemplo, en un problema de reconocimiento de imágenes, las entradas serían las imágenes y las salidas serían las etiquetas que describen lo que hay en cada imagen.
- Modelo: Un algoritmo o una función matemática que intenta aprender la relación entre las entradas y las salidas. Ejemplos de modelos incluyen la regresión lineal, árboles de decisión, redes neuronales, entre otros.
- Función de Pérdida: Una métrica que cuantifica la diferencia entre las predicciones del modelo y las etiquetas reales. El objetivo del proceso de entrenamiento es minimizar esta función de pérdida para mejorar la precisión del modelo.
- Algoritmo de Optimización: Un método para ajustar los parámetros del modelo de manera que se minimice la función de pérdida. El gradiente descendente es uno de los algoritmos de optimización más comunes.
- Validación y Evaluación: Para asegurarse de que el modelo no se sobreajuste (overfitting) a los datos de entrenamiento, se utiliza un conjunto de validación. Posteriormente, el rendimiento del modelo se evalúa en un conjunto de prueba con datos no vistos.
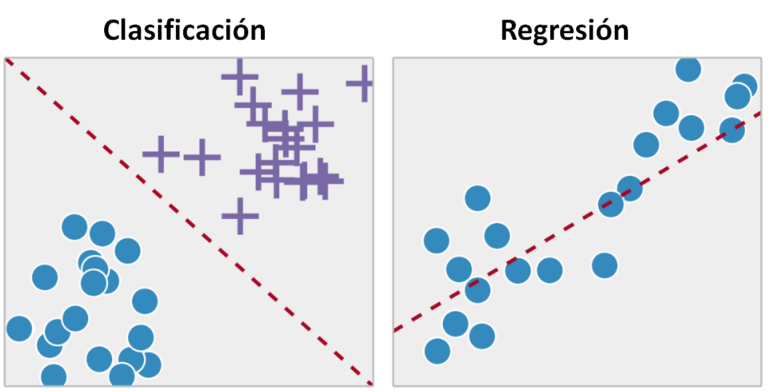
Tipos de Problemas en Aprendizaje Supervisado
- Clasificación: Aquí, la tarea es asignar una etiqueta discreta a cada entrada. Ejemplos comunes incluyen la clasificación de correos electrónicos como spam o no spam, la identificación de objetos en imágenes (como distinguir entre un gato y un perro), y la detección de enfermedades en imágenes médicas.
- Regresión: En este caso, la tarea es predecir un valor continuo. Ejemplos incluyen la predicción de precios de viviendas, la estimación de la demanda de productos, y la previsión de valores bursátiles.
Proceso del Aprendizaje Supervisado
El proceso típico del aprendizaje supervisado sigue varios pasos clave:
- Recopilación de Datos: Obtener un conjunto de datos relevante y etiquetado. La calidad y cantidad de los datos juegan un papel crucial en el rendimiento del modelo.
- Preprocesamiento de Datos: Limpiar y preparar los datos para el entrenamiento. Esto puede incluir la normalización de características, el manejo de valores faltantes y la codificación de variables categóricas.
- División de Datos: Separar los datos en conjuntos de entrenamiento, validación y prueba. El conjunto de entrenamiento se utiliza para ajustar el modelo, el de validación para afinar los hiperparámetros y el de prueba para evaluar el rendimiento final.
- Entrenamiento del Modelo: Utilizar los datos de entrenamiento para ajustar el modelo. Esto implica iterar sobre los datos múltiples veces y ajustar los parámetros del modelo para minimizar la función de pérdida.
- Evaluación del Modelo: Usar los datos de prueba para evaluar el rendimiento del modelo. Métricas comunes incluyen la precisión, el recall, la F1-score para problemas de clasificación y el error cuadrático medio (MSE) para problemas de regresión.
- Ajuste de Hiperparámetros: Refinar los parámetros del modelo para mejorar su rendimiento. Este paso puede implicar el uso de técnicas como la validación cruzada para encontrar la mejor configuración del modelo.
- Implementación: Una vez entrenado y evaluado, el modelo se despliega para hacer predicciones en datos nuevos y no vistos.

Aplicaciones del aprendizaje supervisado
Algunas aplicaciones destacadas del aprendizaje supervisado en diversas áreas son:
- Visión por Computadora
- Reconocimiento de Imágenes: Clasificación de imágenes en categorías predefinidas, como identificar tipos de objetos (perros, gatos, autos).
- Detección de Objetos: Localización de objetos dentro de una imagen, útil en sistemas de seguridad y vehículos autónomos.
- Reconocimiento Facial: Identificación y verificación de personas a través de sus rostros, usado en seguridad y etiquetado de fotos.
- Procesamiento del Lenguaje Natural (NLP)
- Análisis de Sentimientos: Determinación de la opinión o sentimiento expresado en un texto, como comentarios de redes sociales o reseñas de productos.
- Clasificación de Texto: Categorizar documentos o correos electrónicos en temas o etiquetas específicos, como spam vs. no spam.
- Traducción Automática: Traducción de textos de un idioma a otro usando modelos que han sido entrenados con pares de frases en diferentes idiomas.
- Medicina y Salud
- Diagnóstico de Enfermedades: Predicción de enfermedades a partir de imágenes médicas (radiografías, resonancias magnéticas) o datos clínicos (resultados de pruebas, historiales médicos).
- Predicción de Resultados Clínicos: Modelos que predicen la evolución de pacientes basándose en datos históricos y actuales, como la probabilidad de readmisión hospitalaria.
- Finanzas
- Detección de Fraude: Identificación de transacciones fraudulentas en tiempo real mediante el análisis de patrones inusuales en los datos de transacciones.
- Predicción de Riesgo Crediticio: Evaluación de la probabilidad de que un cliente incumpla con el pago de un préstamo.
- Gestión de Inversiones: Modelos que analizan tendencias del mercado para hacer recomendaciones de compra o venta de activos financieros.
- Automatización y Robótica
- Control de Calidad: Inspección automatizada de productos en líneas de producción para detectar defectos.
- Navegación Autónoma: Vehículos autónomos que usan aprendizaje supervisado para reconocer señales de tráfico, peatones y otros vehículos.
- Marketing y Ventas
- Segmentación de Clientes: Agrupación de clientes en segmentos para campañas de marketing personalizadas.
- Predicción de Churn: Identificación de clientes que tienen mayor probabilidad de abandonar un servicio para tomar medidas preventivas.
- Recomendación de Productos: Sugerencias de productos a los usuarios basadas en su historial de compras y comportamiento de navegación.
- Recomendación de Contenido: Sugerencias de películas, música o artículos en plataformas de entretenimiento y noticias.
- Agricultura
- Monitoreo de Cultivos: Análisis de imágenes satelitales o drones para detectar problemas en cultivos como enfermedades o deficiencias nutricionales.
- Clasificación de Productos Agrícolas: Clasificación automática de frutas y verduras por calidad, tamaño o madurez.

Futuro del Aprendizaje Supervisado
El aprendizaje supervisado continúa evolucionando con avances en algoritmos, mayor disponibilidad de datos y aumentos en la capacidad computacional. La combinación con otras técnicas, como el aprendizaje no supervisado y el aprendizaje por refuerzo, promete expandir aún más sus aplicaciones y efectividad.
En resumen, el aprendizaje supervisado es una herramienta poderosa en el arsenal del machine learning, proporcionando soluciones precisas y eficientes a una variedad de problemas del mundo real. A medida que la tecnología avanza, su impacto y alcance seguirán creciendo, moldeando el futuro de la inteligencia artificial y sus aplicaciones.
